About a year ago, I’ve started to wonder what’s the best way to write a position-independent shellcode.
What I was ideally looking for was some kind of “shellcode framework”. Something that would allow me to write nearly regular C/C++ code without too much restrictions and compiles it into a position-independent shellcode.
Sadly, I haven’t found anything like that. So I’ve decided to write my own.
And it’s been a success! The framework can generate x86 and x64 shellcode for both user-mode and kernel-mode, allowing me to write it much like any standard C++ project.
I can even use boost, if I wanted to! I’m kidding. Sort of.
Anyway, this post isn’t about the framework. Nobody cares about that. Rather, it’s about a little discovery I’ve made while working on it.
Subsection Ordering
You can order code and data within sections by creating subsections. That’s not the little discovery, by the way. But, if you didn’t know that, you’re already going to learn something new today!
If you did, you can skip this, umm, section.
Subsections are created by appending a $suffix to the section name.
During linking, these subsections are sorted alphabetically and merged
into their parent section.
For example,
MSVC compiler puts constructors of global C++ objects into .CRT$XCU section.
The CRT initialization code (which is called before main) then iterates
over all the function pointers located between .CRT$XCA and .CRT$XCZ
subsections, calling them one by one:
typedef void (*_PVFV)(void);
#pragma section(".CRT$XCA", long, read)
#pragma section(".CRT$XCZ", long, read)
extern __declspec(allocate(".CRT$XCA")) _PVFV __xc_a[];
extern __declspec(allocate(".CRT$XCZ")) _PVFV __xc_z[];
void
_initterm(
_PVFV* const first,
_PVFV* const last
)
{
for (_PVFV* it = first; it != last; ++it)
{
if (*it == nullptr)
continue;
(**it)();
}
}
_initterm(__xc_a, __xc_z);
Because the subsections are sorted alphabetically, the constructors are
placed between the __xc_a and __xc_z values. In the final PE file,
all the subsections are merged into the .CRT section.
Note that this feature is not specific to MSVC; it is also
supported by ld (GCC) and ldd (Clang/LLVM).
The Story
I wanted my shellcode to have a specific layout:
| Offset | Code/Data | Language |
|---|---|---|
| 0x0000 |
_init:
jmp entry
align 16
|
asm |
| 0x0010 |
extern "C" GlobalData g_data; |
cpp |
| 0x???? |
extern "C"
void entry() { ... }
|
cpp |
The _init function serves as the entry point and must be placed at the very
beginning of the section, aligned to 16 bytes to ensure the g_data variable
is correctly placed at offset 0x0010. This is because I want to be able to
modify the g_data content easily before running the shellcode. And this way,
I can always find it at the same offset.
The _init function should jump over the g_data to the entry function,
which is the actual entry point for the C++ code. The offset for the entry
function is not fixed (0x????), as it depends on the size and layout of
preceding data. But that doesn’t bother me, as it’s not important.
Given that I’m familiar with the subsections feature, I’ve decided to approach it like this:
- Place the
_initfunction (written in MASM) into the.text$aasection. - Place the
g_datavariable (written in C++) into the.text$bbsection. - Place the
entryfunction and rest of the C++ code into the.text$zzsection.
The code will look similar to this:
init.asm:
.CODE
EXTERN entry: PROC
;
; ".text" section is named "_TEXT" in MASM
; and specifying subsections works here as well.
;
_TEXT$aa SEGMENT PARA 'CODE'
_init PROC
jmp entry
align 16
_init ENDP
_TEXT$aa ENDS
END
main.cpp:
struct GlobalData {
...
};
//
// Define the `.text$bb` section.
// Everything after this will be placed in the `.text$bb` section,
// unless another `#pragma section` or `#pragma code_seg` is used.
//
// Note that without defining the `.text$bb` section, the
// __declspec(allocate(".text$bb")) would not work.
//
#pragma code_seg(".text$bb")
extern "C"
__declspec(allocate(".text$bb"))
GlobalData g_data{};
//
// Define the .text$zz section.
// Everything after this will be placed in the .text$zz section.
//
#pragma code_seg(".text$zz")
extern "C"
void entry() {
...
}
void rest_of_the_code() {
...
}
Sounds simple, right? Here’s how I’ve imagined the final .text section
layout would look like:
| Offset | Code/Data | Language | Subsection |
|---|---|---|---|
| 0x0000 |
_init:
jmp entry
align 16
|
asm | .text$aa |
| 0x0010 |
extern "C" GlobalData g_data; |
cpp | .text$bb |
| 0x???? |
extern "C"
void entry() { ... }
|
cpp | .text$zz |
However, after building the shellcode, the resulting section order was not what I expected:
| Offset | Code/Data | Language | Subsection |
|---|---|---|---|
| 0x0000 |
extern "C" GlobalData g_data; |
cpp | .text$bb |
| 0x???? |
_init:
jmp entry
align 16
|
asm | .text$aa ??? |
| 0x???? |
extern "C"
void entry() { ... }
|
cpp | .text$zz |
Huh? Why is the .text$aa section placed between .text$bb and .text$zz?
The Investigation
Something’s not right. Either the order of the alphabet has changed, or I’ve missed something.
The linker is supposed to sort the subsections. What is the input of the linker? Object files. What do object files contain? Code and data. But also the sections they belong to. So let’s take a closer look at the object files.
First, the C++ object file containing the g_data variable:
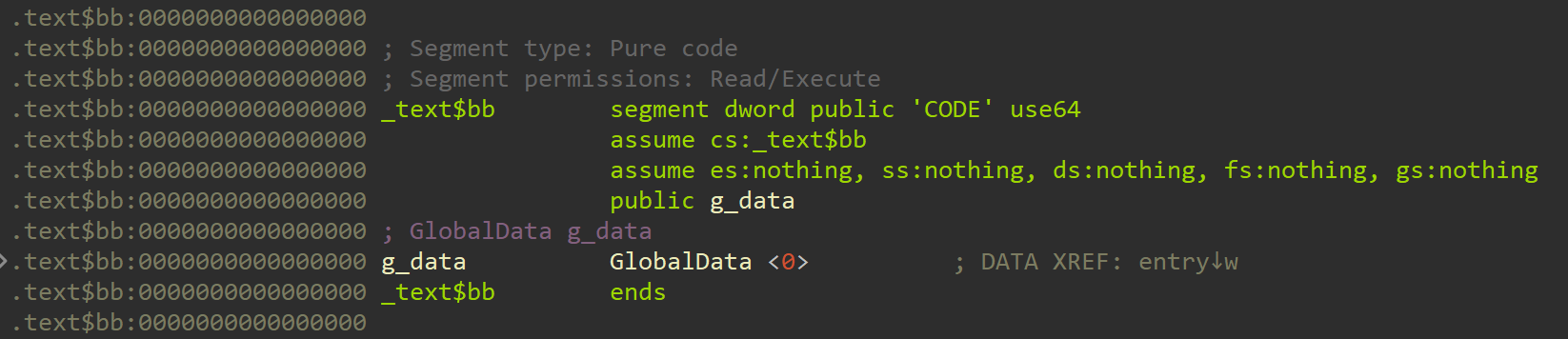
Nothing suspicious here. The .text$bb section contains the g_data variable,
as expected.
Next, the MASM object file containing the _init function:
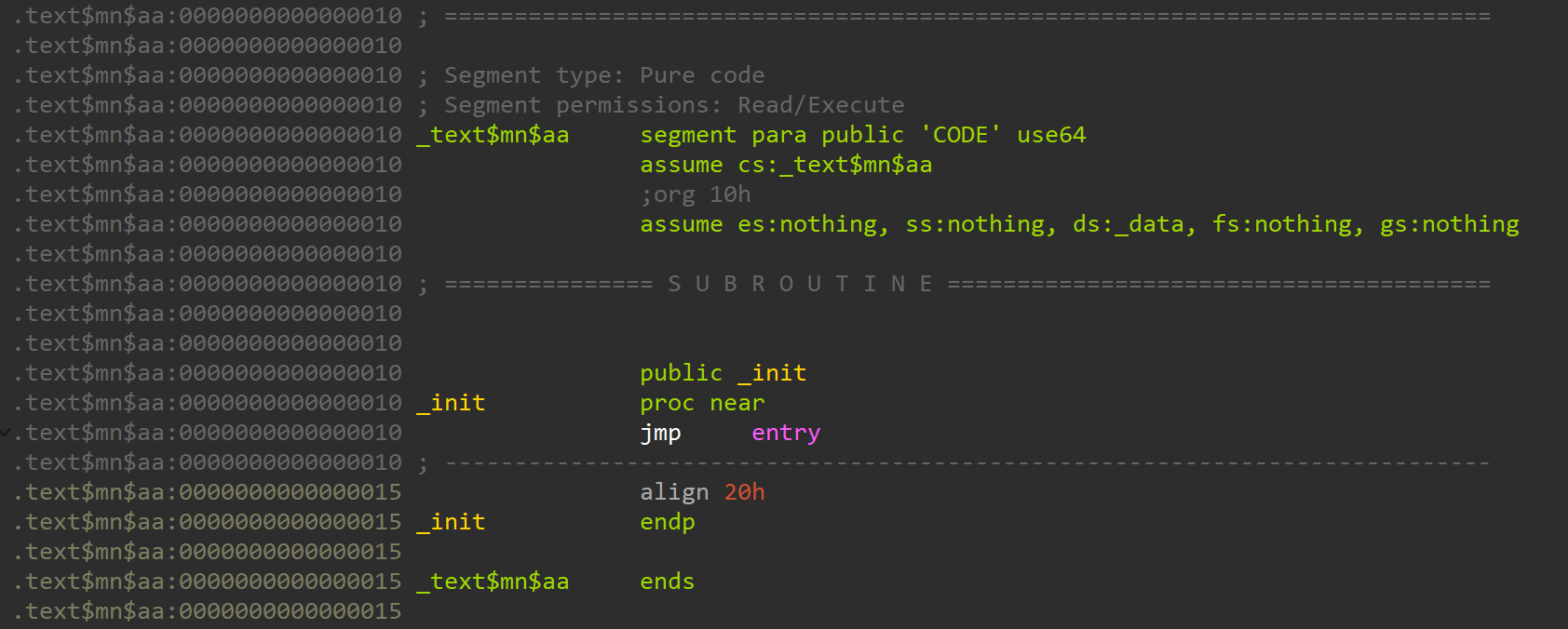
Excuse me, what the hell is .text$mn?
The .text$mn Section
It looks like MASM is inserting mn into the section name.
Therefore, the linker sees this:
| Offset | Code/Data | Language | Subsection |
|---|---|---|---|
| 0x0000 |
extern "C" GlobalData g_data; |
cpp | .text$bb |
| 0x???? |
_init:
jmp entry
align 16
|
asm | .text$mn$aa |
| 0x???? |
extern "C"
void entry() { ... }
|
cpp | .text$zz |
Now it makes sense - at least why the order is the way it is.
So, does it mean that if we place the g_data variable explicitly
in the .text$mn$bb section, the order will be correct?
| Offset | Code/Data | Language | Subsection |
|---|---|---|---|
| 0x0000 |
_init:
jmp entry
align 16
|
asm | .text$mn$aa |
| 0x0010 |
extern "C" GlobalData g_data; |
cpp | .text$mn$bb |
| 0x???? |
extern "C"
void entry() { ... }
|
cpp | .text$zz |
And it does! After building the shellcode, the order is finally correct.
But Why?
I’ve tried to find any information about the .text$mn section, but there was
nothing. No official documentation, no blog posts, no forum threads. But there
are casual mentions of the .text$mn section in various places. Most of them
are snippets from the dumpbin output, showing the section name.
However, I’ve also found couple of interesting mentions in the source code of various GitHub projects, such as Unreal Engine or VirtualBox.
One of the mentions stood out, though:
#pragma code_seg(".text$mn$cpp")
This gave me a confirmation that I’m not the only one who has encountered this. The project unsurprisingly also happens to be of a similar nature to mine.
Can We Disable It?
I haven’t been satisfied with the workaround. I wanted to know if there’s
any way to force MASM to not insert the mn into the section name.
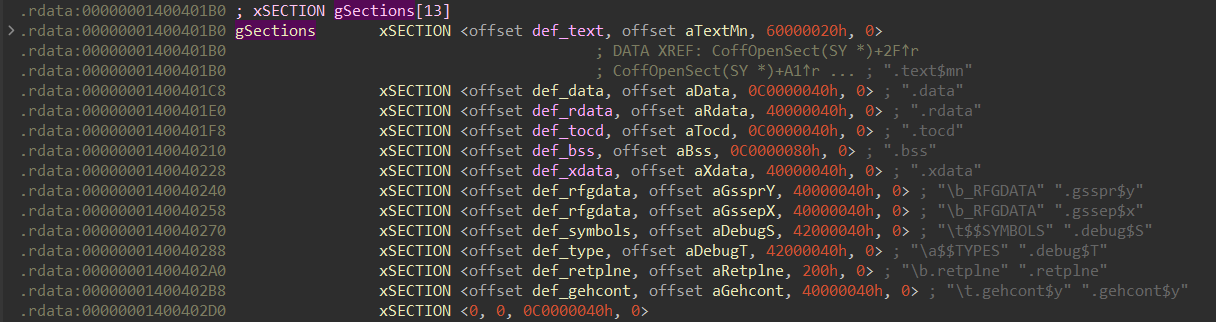
Naturally, I’ve opened ml64.exe
in IDA and started to look around for any references to the mn string.
Successfully:
Note: Most of the variables, structures and their fields are named by me during the analysis. The names are not in the
ml64.exe’s PDB.
Here we can see some kind of array of structures similar to this:
struct xSECTION {
const char* name1;
const char* name2;
uint32_t characteristics;
uint32_t _probably_alignment;
};
characteristics is a bitmask of section characteristics, such as IMAGE_SCN_CNT_CODE.
The name1 and name2 fields are pointers to some strings resembling the section names:
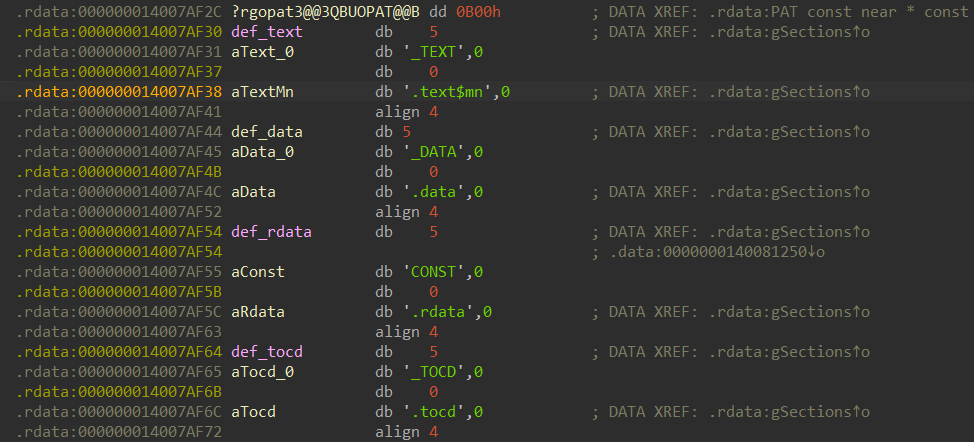
I’ve looked for any references to the gSections array.
There was basically only one:
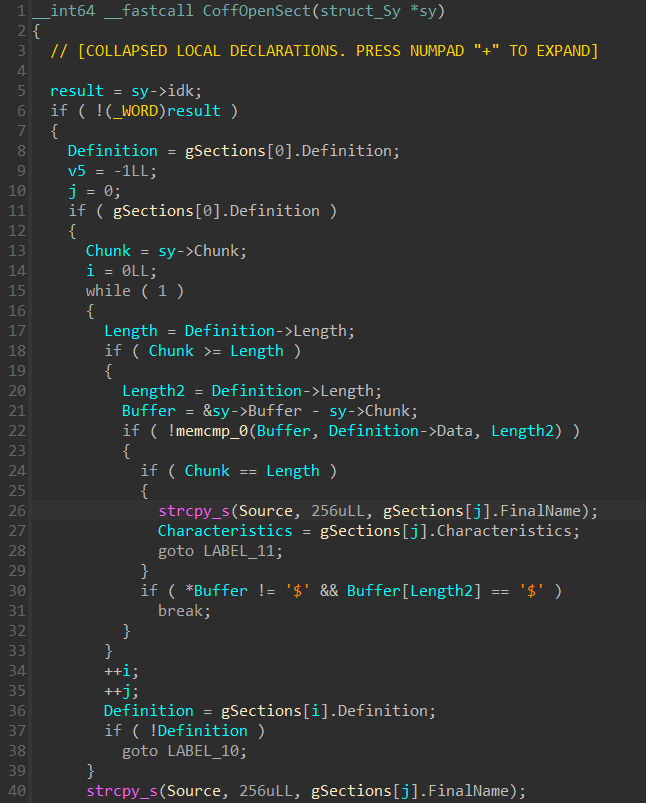
Now it was clear.
In MASM, you can’t specify the section name with the dot (.) character.
This is a syntax error:
.text SEGMENT PARA 'CODE'
...
.text ENDS
Instead, you have to use the _TEXT keyword:
_TEXT SEGMENT PARA 'CODE'
...
_TEXT ENDS
The same applies to the .data section, which has to be written as _DATA.
And it also applies to the other sections mentioned in the gSections array.
And the CoffOpenSect function is responsible for this translation.
Unfortunately, we can see that
the _TEXT section is hardcoded to be translated to .text$mn.
There’s no way to turn it off.
This also applies to the x86 version of MASM and probably even to the ARM64 version, although I haven’t checked that.
Conclusion
Sadly, I haven’t been able to figure out why it is necessary for MASM
to translate the _TEXT section to .text$mn, nor have I figured out
what the mn stands for.
However, a comment in the VirtualBox source code suggests that this behavior might not have been there forever.
Either way, it’s there. And it’s worth knowing about it, especially if you’re combining MASM with MSVC and are particularly picky about the section order.
Update
Not long after posting this on Twitter
I was contacted by Evan McBroom (thank you!)
who informed me that in fact you can avoid the .text$mn subsection.
The trick is to use the ALIAS keyword within the SEGMENT directive, like this:
_EXAMPLE SEGMENT PARA ALIAS('.text$aa') 'CODE'
...
_EXAMPLE ENDS
The catch - as you might have spotted - is to not use the _TEXT keyword.
Apparently, _TEXT has special handling in MASM, and attempting
to ALIAS it will result in error.
You don’t have to prefix the section name with the underscore (_)
character, though. This is valid as well:
EXAMPLE SEGMENT PARA ALIAS('.text$aa') 'CODE'
...
EXAMPLE ENDS
Note that you can use both single-quote (') and double-quote (") characters
around the section name.
It’s not a pretty solution, but it’s a solution nonetheless.
Update #2
sixtyvividtails
has pointed out that the mn isn’t specific to MASM; in fact, all code compiled
with MSVC defaults to the .text$mn section.
I’ve verified this to be true. I also feel a bit stupid for not realizing this
sooner - I’ve always examined the section names of object files where I had
explicitly #pragma‘d the sections.
He also has a theory that the mn stands for main. I’m waiting for Bill Gates
to confirm this.
However, since the MSVC does this by default, it sheds new light on the purpose
of the .text$mn subsection - it allows for the ordering of code within the
.text section for the CRT itself. And mn designation is simply a convenient
choice, picked to be exactly in the middle of the alphabet.
This is also supported by the fact that the MSVC CRT libraries already use
multiple .text subsections, including:
.text$di.text$mn.text$x.text$yd
References
-
CRT initialization:
https://learn.microsoft.com/en-us/cpp/c-runtime-library/crt-initialization - Raymond Chen’s blog posts:
-
Using linker segments and __declspec(allocate(…)) to arrange data in a specific order:
https://devblogs.microsoft.com/oldnewthing/20181107-00/?p=100155 -
Gotchas when using linker sections to arrange data, part 1:
https://devblogs.microsoft.com/oldnewthing/20181108-00/?p=100165 -
Gotchas when using linker sections to arrange data, part 2:
https://devblogs.microsoft.com/oldnewthing/20181109-00/?p=100175
-
-
IMAGE_SECTION_HEADERstructure:
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_section_header -
Mention of the
.text$mnin UnrealEngine:
https://github.com/EpicGames/UnrealEngine/blob/1308e62273a620dd4584b830f6b32cd8200c2ad3/Engine/Source/Programs/UnrealBuildAccelerator/Common/Private/UbaObjectFileCoff.cpp#L484 -
Mention of the
.text$mnin VirtualBox:
https://github.com/mirror/vbox/blob/74117a1cb257c00e2a92cf522e8e930bd1c4d64b/src/VBox/ValidationKit/bootsectors/bs3kit/VBoxBs3ObjConverter.cpp#L2148 - Mention of the
.text$mnin a “SC” project:
https://github.com/rbmm/SC/blob/c2711cb91f2b6acedc0b1df94a31fbdf3346e189/LFM/stdafx.h#L1